







Archive for November 2014
Have you funded this already? LUNAR MISSION ONE@ Kickstarter
COOL! This project is targeting on £600,000 by 18 Dec, 2014.

Lunar Mission One is a crowd funding project aiming to drill at the South Pole of the Moon and analyze rock sample. It is hoped that the data will unveil the geological composition of the Moon, the ancient relationship it shares with our planet and the effects of asteroid bombardment.

Full version of description can be found here:
Lunar Mission One is a crowd funding project aiming to drill at the South Pole of the Moon and analyze rock sample. It is hoped that the data will unveil the geological composition of the Moon, the ancient relationship it shares with our planet and the effects of asteroid bombardment.
Full version of description can be found here:
Back the project now:
LUNAR MISSION ONE: A new lunar mission for everyone, KictStarter.com
image source: LUNAR MISSION ONE: A new lunar mission for everyone
Tag :
general,
kickstarter,
LEGO and Scientific Researches
LEGO is my favorite toy when I was a kid. I enjoyed to build different spaceships and features with my limited Lego blocks. It was fun and and full of creation.

There are many different variations and products now for Lego. However, its' flexibility and simplicity (as basic building block) are remain unchanged. These allows researchers to easily build their own scientific tools for scientific experiments. But besides building robots, what else Lego can help researchers?
Take a look and see if they can inspire you something... Iowa State engineers turn LEGO bricks into a scientific tool to study plant growth
![]()

Growing bones with Lego

The University of Glasgow Raspberry Pi Cloud project

LEGO® AFM
Lego for the Lab
LEGO Pirate Proves Existence of Super Wave
Robotics with LEGO
Using LEGO® to simulate ESA's touchdown on a comet
A LEGO Counting problem

Soft machines made like Lego

image source: Move Over, Boys: Lego Releases Female Scientist Playset
There are many different variations and products now for Lego. However, its' flexibility and simplicity (as basic building block) are remain unchanged. These allows researchers to easily build their own scientific tools for scientific experiments. But besides building robots, what else Lego can help researchers?
Take a look and see if they can inspire you something... Iowa State engineers turn LEGO bricks into a scientific tool to study plant growth

Growing bones with Lego

The University of Glasgow Raspberry Pi Cloud project

LEGO® AFM
Lego for the Lab
LEGO Pirate Proves Existence of Super Wave
Robotics with LEGO
Using LEGO® to simulate ESA's touchdown on a comet

Soft machines made like Lego

image source: Move Over, Boys: Lego Releases Female Scientist Playset
Quantum dots and LCD TV
It is again from MIT! QD Vision, a spin-off of MIT, applying quantum dots to LCD TV and making it more colorful and more energy saving.


What to know more?
http://newsoffice.mit.edu/2014/startup-quantum-dot-tv-displays-1119, MIT News
http://www.qdvision.com/, QD Vision
http://www.sony.ee/hub/lcd-television/benefits/tv-picture-quality/article/triluminos, Sony
Related News:
Interview: QD Vision's Carlson And Coe-Sullivan Discuss Why Color Matters
Samsung, LG turn to quantum dots as OLED still too pricey, Reuters
"Last June, Sony used QD Vision’s product, called Color IQ, in millions of its Bravia “Triluminos” televisions, marking the first-ever commercial quantum-dot display. In September, Chinese electronics manufacturer TCL began implementing Color IQ into certain models."

What to know more?
http://newsoffice.mit.edu/2014/startup-quantum-dot-tv-displays-1119, MIT News
http://www.qdvision.com/, QD Vision
http://www.sony.ee/hub/lcd-television/benefits/tv-picture-quality/article/triluminos, Sony
Related News:
Interview: QD Vision's Carlson And Coe-Sullivan Discuss Why Color Matters
Samsung, LG turn to quantum dots as OLED still too pricey, Reuters
A comparative encyclopedia of DNA elements in the mouse genome
Corresponding authors: John A. Stamatoyannopoulos, Michael P. Snyder,
Roderic Guigo, Thomas R. Gingeras, David M. Gilbert, Ross C. Hardison,
Michael A. Beer, Bing Ren
Mouse ENCODE Consortium
Nature 515, 355–364 (20 November 2014) doi:10.1038/nature13992

The laboratory mouse shares the majority of its protein-coding genes with humans, making it the premier model organism in biomedical research, yet the two mammals differ in significant ways. To gain greater insights into both shared and species-specific transcriptional and cellular regulatory programs in the mouse, the Mouse ENCODE Consortium has mapped transcription, DNase I hypersensitivity, transcription factor binding, chromatin modifications and replication domains throughout the mouse genome in diverse cell and tissue types. By comparing with the human genome, we not only confirm substantial conservation in the newly annotated potential functional sequences, but also find a large degree of divergence of sequences involved in transcriptional regulation, chromatin state and higher order chromatin organization. Our results illuminate the wide range of evolutionary forces acting on genes and their regulatory regions, and provide a general resource for research into mammalian biology and mechanisms of human diseases.
The electronic version of this article is the complete one and can be found online at: http://www.nature.com/nature/journal/v515/n7527/full/nature13992.html
More about Mouse ENCODE Consortium:
"To complement the human Encyclopedia of DNA Elements (ENCODE) project the Mouse ENCODE Consortium (funded by the National Human Genome Research Institute from 2009-2012) applied the same technologies and experimental pipelines developed for human ENCODE in order to annotate functional elements encoded in the mouse genome. The data and analyses from Mouse ENCODE will enable a broad range of mouse genomics and translational research efforts
The Mouse ENCODE Consortium consisted of a number of Data Production Centers and made use of the human ENCODE Data Coordination Center (DCC) at the University of California, Santa Cruz (currently at Stanford University). Production Centers generally focused on different data types, including transcription factor and polymerase occupancy, DNaseI hypersensitivity, histone modification, and RNA transcription.
Work on Mouse ENCODE is continuing with further funding from the National Human Genome Research Institute under the ENCODE 3 program, which supports both human and mouse studies."
image source: http://twitter.com/nature
Roderic Guigo, Thomas R. Gingeras, David M. Gilbert, Ross C. Hardison,
Michael A. Beer, Bing Ren
Mouse ENCODE Consortium
Nature 515, 355–364 (20 November 2014) doi:10.1038/nature13992
The laboratory mouse shares the majority of its protein-coding genes with humans, making it the premier model organism in biomedical research, yet the two mammals differ in significant ways. To gain greater insights into both shared and species-specific transcriptional and cellular regulatory programs in the mouse, the Mouse ENCODE Consortium has mapped transcription, DNase I hypersensitivity, transcription factor binding, chromatin modifications and replication domains throughout the mouse genome in diverse cell and tissue types. By comparing with the human genome, we not only confirm substantial conservation in the newly annotated potential functional sequences, but also find a large degree of divergence of sequences involved in transcriptional regulation, chromatin state and higher order chromatin organization. Our results illuminate the wide range of evolutionary forces acting on genes and their regulatory regions, and provide a general resource for research into mammalian biology and mechanisms of human diseases.
The electronic version of this article is the complete one and can be found online at: http://www.nature.com/nature/journal/v515/n7527/full/nature13992.html
More about Mouse ENCODE Consortium:
"To complement the human Encyclopedia of DNA Elements (ENCODE) project the Mouse ENCODE Consortium (funded by the National Human Genome Research Institute from 2009-2012) applied the same technologies and experimental pipelines developed for human ENCODE in order to annotate functional elements encoded in the mouse genome. The data and analyses from Mouse ENCODE will enable a broad range of mouse genomics and translational research efforts
The Mouse ENCODE Consortium consisted of a number of Data Production Centers and made use of the human ENCODE Data Coordination Center (DCC) at the University of California, Santa Cruz (currently at Stanford University). Production Centers generally focused on different data types, including transcription factor and polymerase occupancy, DNaseI hypersensitivity, histone modification, and RNA transcription.
Work on Mouse ENCODE is continuing with further funding from the National Human Genome Research Institute under the ENCODE 3 program, which supports both human and mouse studies."
image source: http://twitter.com/nature
Carbon Dioxide Emission Pattern in one Year - the US, China, and Europe are the main polluters

Scientists at NASA modelling the movement of carbon dioxide in a year. In the video, as expected, the US, China, and Europe are clearly revealed as the main polluters. Watch the Youtube video below:
Here are some other findings in the video:
"Earth's carbon dioxide levels peak in the spring, and then drop in summer, when Northern Hemisphere plant growth absorbs gas from the atmosphere"
"In North America, the major emissions sources are in the Midwest and along the East Coast. Westerly winds in the Gulf Stream carry the greenhouse gas eastward over the Atlantic Ocean, the model shows"
"In Asia, the Himalayas block and divert winds that swirl around the high mountains. East of the Himalayas, these winds pick up carbon dioxide emissions from the industrialized Asian countries and carry the gas toward the Pacific Ocean"
"In the Southern Hemisphere, plumes of carbon dioxide and carbon monoxide rise from forest fires in South America and southern Africa"
Check the complete news on "Watch Carbon Pollution Spread Across the Planet"@ livescience.com
Nature Index
One more indexing service is introduced by Nature recently.
"The Nature Index tracks the affiliations of high-quality scientific articles. Updated monthly, the Nature Index presents recent research outputs by institution and country. Use the Nature Index to interrogate publication patterns and to benchmark research performance."

Find out more: www.natureindex.com
image source: http://www.nature.com/nature/supplements/nature-index-2014-global
"The Nature Index tracks the affiliations of high-quality scientific articles. Updated monthly, the Nature Index presents recent research outputs by institution and country. Use the Nature Index to interrogate publication patterns and to benchmark research performance."
Find out more: www.natureindex.com
image source: http://www.nature.com/nature/supplements/nature-index-2014-global
Next-generation pathogen genomics
* Corresponding author: George M Weinstock george.weinstock@jax.org
The Jackson Laboratory for Genomic Medicine, Farmington, Connecticut, USA
[more about author]
Genome Biology 2014, 15:528 doi:10.1186/s13059-014-0528-6

In the early 1990s, one of us was involved in one of the first projects to sequence a bacterial genome, the meager 1.1 Mb chromosome of Treponema pallidum, the causative agent of syphilis. Completing the project ultimately took about seven years (until published in 1998 [1]), over US$1.8 million in National Institutes of Health grants (R01AI031068 and R01AI040390) [2], and required pooling forces with The Institute for Genomic Research. Recently, that original T. pallidum strain was re-sequenced to get a ‘perfect’ sequence, a process that took a few days and cost only hundreds of dollars [3]. The original sequencing was performed with the dideoxy-chain termination technique using slab gel electrophoresis instruments. Newly developed software was used for genome assembly and data management and analysis. The latter re-sequencing was performed with next-generation sequencing (NGS) technology and mature software tools. Such is the enormous progress in microbial genome sequencing in the last 20 years.
The mind-boggling evolution of DNA sequencing and bioinformatics technologies is driving a new era of pathogen research. Recent studies of old, well-scrutinized pathogens are now greatly extended based on the sequencing of thousands of strains from collections [4],[5]. This increased density of genetic data for individual species allows new insights and definition of mechanisms, just as an aerial photograph gives a clearer picture of the landscape as the pixel density increases. Such large-scale studies, now possible with the increased throughput and lower cost of sequencing, allow a more comprehensive picture of a species’ gene pool (the pan-genome), population genetic and/or evolutionary analyses, and more accurate insights into epidemiology, to name a few advances. In the realm of epidemiology, NGS of pathogens is now pushing into the applied genomics area of the clinic, with, for example, studies of clinical outbreaks that can now precisely define complex transmission chains [6],[7]. Perilous clinical challenges posed by new antibiotic-resistant organisms benefit from NGS which can identify mutations, thereby defining mechanisms by which resistance is acquired [8],[9], as well as discerning new threats from resistance genes found in whole genome sequences [10].
It is in this context of a new era in pathogen genomics that this special issue of Genome Biology and Genome Medicine on the Genomics of Infectious Diseases has been assembled. It coincides with an exhilarating time for pathogen genomics research and covers a broad range of bacterial, viral, and parasitic pathogens. Genomic analysis, and sequencing in particular, is agnostic, and applies equally well to the diverse types of pathogens studied in this special issue. Pathogen genomics continues to be an area of some urgency. We need look no further than the current challenges of containing Ebola virus outbreaks or the emergence and expansion of new antibiotic-resistant bacteria, such as carbapenemase-producing Klebsiella pneumoniae, to be reminded that infectious disease is not, and will never be, a solved problem. Rather, only by dramatic technological innovation, such as offered by NGS, can we keep up with the pathogenic population.
Genome sequencing continues to advance and provide new tools and applications for pathogen research. Sequencing can now be performed on hundreds of strains in parallel in overnight instrument runs, and this drives forward the data density for the description of genomes and gene expression patterns. Metagenomic application of NGS is another bright new area, affording new culture-independent detection of pathogens in clinical samples as well as illuminating interactions between the pathogen and resident microbiome. One looks forward to future applications of this information to combat infection and restore health, possibly with reduced dependence on antibiotics.
The electronic version of this article is the complete one and can be found online at: http://genomebiology.com/2014/15/11/528
image source: http://commons.wikimedia.org/wiki/File:Agarose_gel_slab_for_DNA_Analysis,_after_the_Electrophoresis_run.jpg
The Jackson Laboratory for Genomic Medicine, Farmington, Connecticut, USA
[more about author]
Genome Biology 2014, 15:528 doi:10.1186/s13059-014-0528-6
In the early 1990s, one of us was involved in one of the first projects to sequence a bacterial genome, the meager 1.1 Mb chromosome of Treponema pallidum, the causative agent of syphilis. Completing the project ultimately took about seven years (until published in 1998 [1]), over US$1.8 million in National Institutes of Health grants (R01AI031068 and R01AI040390) [2], and required pooling forces with The Institute for Genomic Research. Recently, that original T. pallidum strain was re-sequenced to get a ‘perfect’ sequence, a process that took a few days and cost only hundreds of dollars [3]. The original sequencing was performed with the dideoxy-chain termination technique using slab gel electrophoresis instruments. Newly developed software was used for genome assembly and data management and analysis. The latter re-sequencing was performed with next-generation sequencing (NGS) technology and mature software tools. Such is the enormous progress in microbial genome sequencing in the last 20 years.
The mind-boggling evolution of DNA sequencing and bioinformatics technologies is driving a new era of pathogen research. Recent studies of old, well-scrutinized pathogens are now greatly extended based on the sequencing of thousands of strains from collections [4],[5]. This increased density of genetic data for individual species allows new insights and definition of mechanisms, just as an aerial photograph gives a clearer picture of the landscape as the pixel density increases. Such large-scale studies, now possible with the increased throughput and lower cost of sequencing, allow a more comprehensive picture of a species’ gene pool (the pan-genome), population genetic and/or evolutionary analyses, and more accurate insights into epidemiology, to name a few advances. In the realm of epidemiology, NGS of pathogens is now pushing into the applied genomics area of the clinic, with, for example, studies of clinical outbreaks that can now precisely define complex transmission chains [6],[7]. Perilous clinical challenges posed by new antibiotic-resistant organisms benefit from NGS which can identify mutations, thereby defining mechanisms by which resistance is acquired [8],[9], as well as discerning new threats from resistance genes found in whole genome sequences [10].
It is in this context of a new era in pathogen genomics that this special issue of Genome Biology and Genome Medicine on the Genomics of Infectious Diseases has been assembled. It coincides with an exhilarating time for pathogen genomics research and covers a broad range of bacterial, viral, and parasitic pathogens. Genomic analysis, and sequencing in particular, is agnostic, and applies equally well to the diverse types of pathogens studied in this special issue. Pathogen genomics continues to be an area of some urgency. We need look no further than the current challenges of containing Ebola virus outbreaks or the emergence and expansion of new antibiotic-resistant bacteria, such as carbapenemase-producing Klebsiella pneumoniae, to be reminded that infectious disease is not, and will never be, a solved problem. Rather, only by dramatic technological innovation, such as offered by NGS, can we keep up with the pathogenic population.
Genome sequencing continues to advance and provide new tools and applications for pathogen research. Sequencing can now be performed on hundreds of strains in parallel in overnight instrument runs, and this drives forward the data density for the description of genomes and gene expression patterns. Metagenomic application of NGS is another bright new area, affording new culture-independent detection of pathogens in clinical samples as well as illuminating interactions between the pathogen and resident microbiome. One looks forward to future applications of this information to combat infection and restore health, possibly with reduced dependence on antibiotics.
The electronic version of this article is the complete one and can be found online at: http://genomebiology.com/2014/15/11/528
image source: http://commons.wikimedia.org/wiki/File:Agarose_gel_slab_for_DNA_Analysis,_after_the_Electrophoresis_run.jpg
{kind=link}
Did you vote on Breakthrough of the Year 2014?
Go and Vote it Now at Breakthroughs.sciencemag.org!

Landing on a comet
Explaining the global warming pause
DNA of our daily bread

An easy cure for hepatitis C
Unzipping wood
Roll on, big river
The birth of birds
A giant swimming dinosaur
Robots that cooperate
The rise of the CubeSat
Young blood fixes olds
Giving life a bigger genetic alphabet
Life lurks under Antarctic ice
Asia's oldest art gallery
Manipulating memories
The supercluster we call home
Humans can smell a trillion scents
Chips that mimic the brain
Cells that might cure diabetes
image source: http://breakthroughs.sciencemag.org/
Landing on a comet
 |
| Rosetta, the most ambitious space mission ever from Europe, is in orbit around comet 67P/Churyumov-Gerasimenko, which is just beginning to heat up and flare its stores of ice. On 12 November, the probe will drop Philae, a washing machine–sized lander with harpoons to help it stick to the fluffy surface. |
Explaining the global warming pause
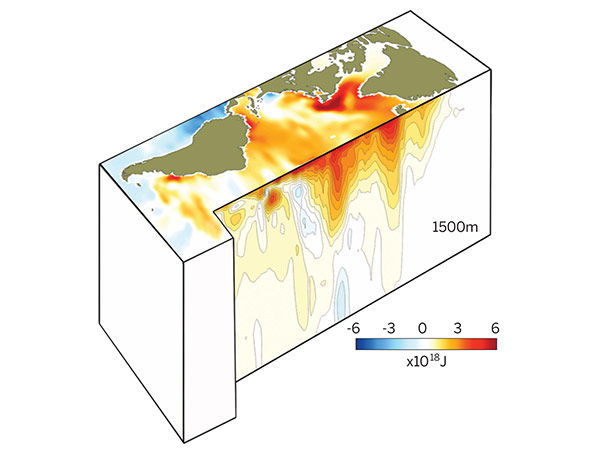 |
| The so-called pause or hiatus in global warming has been a preoccupation for climate scientists for the last decade: Why has a steady rise in global mean air temperatures flattened out? This year it turned out that Earth has been warming all along—in the oceans, not necessarily the air. The magnitude of the ocean heat sinks is still being debated, but one thing is certain: Some of the trapped heat will eventually return to the air. |
DNA of our daily bread

An easy cure for hepatitis C
 |
| Until May 2011, the only treatment against hepatitis C virus (HCV) was 48 weeks of ribavirin pills and weekly injections of interferon. The regimen had serious side effects and often did not work. But that month, HCV treatment changed when two drugs that directly act against the virus came to market. This year better drugs with fewer side effects have been approved or are far along in development, and it may soon become routine to cure HCV in as little as 8 weeks. The biggest downside: These drugs sell for as much as $1000 per pill. |
Unzipping wood
 |
| To turn trees and other woody plants into biofuels, engineers must chemically chop up the woody lignins. The sugar-rich cellulose can then be turned into sugars that yeast can ferment into ethanol. This year researchers engineered plants to produce a modified lignin that didn't stop plants from growing, but that could be unzipped at the end of their lives, releasing the sugars to more easily make biofuels. |
Roll on, big river
 |
| In the western United States, water is so scarce and intensively managed that rivers rarely run free. So an experimental flood in the Colorado River delta in March was cause for celebration. For the first time in many years, significant amounts of water flowed down the dry river bed to its mouth in the Gulf of California. Scientists planned the event and were on hand to study the benefits to native vegetation. |
The birth of birds
 |
| Scientists have known for years that birds are dinosaurs: one offshoot of a reptilian family tree whose other branches went extinct tens of millions of years ago. This year, researchers found feathers in a type of dinosaur distantly related to living birds, suggesting that feathers—that most birdlike of traits—were widespread among dinosaurs. This study and others suggest that birdlike adaptations extended deep into the past, implying a long, slow gestation for one of the most colorful, varied, and successful lineages of animals on Earth today. |
A giant swimming dinosaur
 |
| A new fossil of the sail-backed dinosaur Spinosaurus shows that it was not just the biggest meat-eating dinosaur, at 15 meters in length, but also the only dinosaur adapted for swimming. Though it might have bested T. rex in a fight, it probably ate fish. |
Robots that cooperate
 |
| This year several teams showed that robots, like people, can accomplish more by working together. In one study, a thousand quarter-sized robots came together like a marching band to form squares, letters, and other formations. Inspired by termites, another team built robots that worked together to build 3D structures. Other, airborne robots mimic flocking birds. |
The rise of the CubeSat
 |
| 2014 has seen a record number of CubeSat launches. These pint-sized, low-cost satellites are taking advantage of increased access to space and advances in cheap, powerful sensors and electronics that allow them to do real science. In time, space science may be done by constellations of tiny, low-cost satellites, rather than a single, complex and pricey mission. |
Young blood fixes olds
 |
| Experiments in which the circulatory systems of an old and young mouse are stitched together have found that young blood—as well as a factor isolated from the blood—can rejuvenate the brain and muscles of an aging mouse. Doctors are now testing blood plasma from young donors in people with Alzheimer's disease. |
Giving life a bigger genetic alphabet
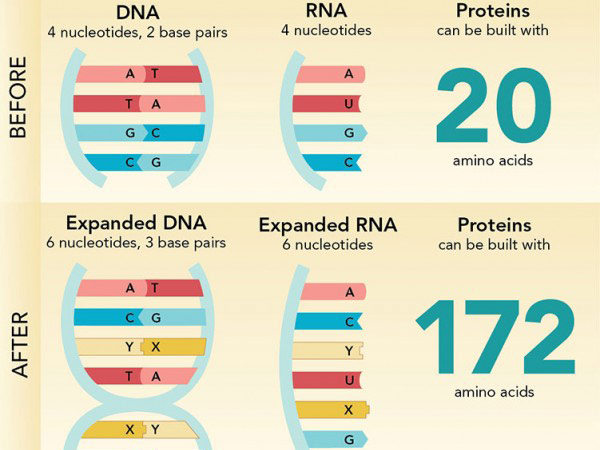 |
| Researchers have expanded the DNA repertoire beyond the G-C and A-T pairs found in nature by creating a pair of novel letters, X bound to Y. This year they managed to insert these extra letters into living bacteria. Next up: using the extra DNA letters to code for amino acids that are not normally part of proteins in organisms. |
Life lurks under Antarctic ice
 |
| A diverse microbial ecosystem is thriving under 800 meters of ice in Lake Whillans, a subglacial lake in West Antarctica. A U.S.-led team of scientists drilled into the ice in January 2013, recovering sediment and water samples. This year, the team announced that the water, sealed off from the surface for more than 100,000 years, teemed with life. |
Asia's oldest art gallery
 |
| The world's oldest cave art may lie not in Europe but halfway around the globe in an Indonesian cave, where scientists have dated handprints and strange-looking pigs in red and mulberry to more than 35,000 years ago. The find suggests that modern humans were a creative bunch by the time they left Africa and began settling the world. |
Manipulating memories
 |
| One of 2013's cool-yet-creepy neuroscience highlights occurred when researchers instilled a fake memory of fear in mice, by manipulating neurons with light. This year, scientists took the method further, using a similar technique to switch good memories to fearful ones and bad memories to pleasant ones. |
The supercluster we call home
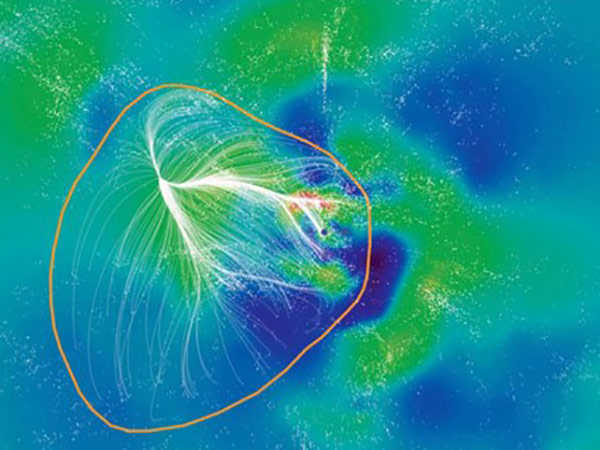 |
| Galaxies are trifles next to the structures that astronomers have been mapping lately: galaxy clusters and superclusters of many thousands of galaxies. But where do we and our Milky Way fit in this picture? By combining the best galaxy catalog to date with other data about galactic motions, astronomers have now identified our home supercluster and its nearest neighbors. They call it Laniakea, from a Hawaiian phrase meaning "spacious heaven." |
Humans can smell a trillion scents
 |
| It's time to stop dissing the human sense of smell. Although we may not be able to detect (or appreciate) as many smells as our canine companions, this year researchers calculated that humans can distinguish roughly a trillion scents—far more than the roughly 10,000 odors that had been estimated before. |
Chips that mimic the brain
 |
| Computer chips keep getting better and faster—but their basic architecture hasn't changed for half a century. This year chipmakers broke the mold, creating the first large-scale "neuromorphic" chips, designed to process information in ways more akin to living brains. The chips promise to vastly improve the ability of machines to carry out perceptual tasks, such as vision, and thus could improve everything from robotics to interpreting data from vast arrays of environmental sensors. |
Cells that might cure diabetes
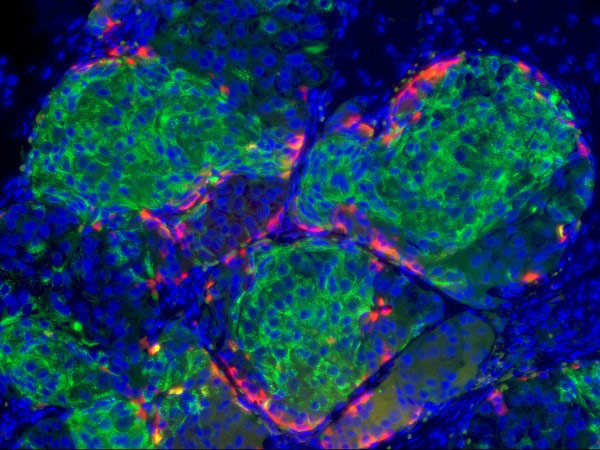 |
| After more than a decade of trying, scientists have turned human stem cells into pancreatic β cells that secrete insulin—the very cells that are missing in type 1 diabetics. The recipe is complex, and the cells—made from embryonic stem cells or reprogrammed adult cells—would still face rejection by diabetics’ immune system if transplanted into patients. But the achievement brings a possible stem cell–based treatment for diabetes a step closer. |
image source: http://breakthroughs.sciencemag.org/
Green chemistry and the biorefinery concept
* Corresponding author: Rafal Bogel-Lukasik rafal.lukasik@lneg.pt
Laboratório Nacional de Energia e Geologia, Unidade de Bioenergia, 1649-038, Lisboa, Portugal
[more about author]
Sustainable Chemical Processes 2013, 1:18 doi:10.1186/2043-7129-1-18

Excerpt
"Among the several definitions of biorefinery, the most widely used and recently accomplished by International Energy Agency (IEA) Bioenergy Task 42 is “Biorefining is the sustainable processing of biomass into a spectrum of marketable products and energy”. The biorefinery is an industrial facility (or network of facilities) that cover an extensive range of combined technologies aiming to full sustainable transformation of biomass into their building blocks with the concomitant production of biofuels, energy, chemicals and materials, preferably of added-value [4]. The biorefinery concept embraces a whole crop approach of biomass conversion pathways leading to a whole portfolio of valuable products, drawing direct similarities to today’s fossil oil refineries, in which multiple fuels, basic chemicals, intermediate products and sophisticated products are produced from petroleum [5,6]. To accomplish these needs science developed many less energy-requiring and less waste-generation technologies. However, still need of a new investment requirements and a perceived high risk of adoption of new technologies are slowing down the implementation of new processes. The solution of this problem is the development of more sustainable technologies that significantly increase the resource efficiency of chemical processes and reduce the operation time of such technologies. In addition, these new technologies should be accomplished in chemical industries by the introduction of chemical processes that do not produce contaminants, but only non-toxic commodities and recyclable or easily degradable materials. Industries should be based on ideal processes that start from non-polluting starting materials, lead to no secondary or concomitant products and require no solvents in order to carry out any chemical conversion or to isolate and purify the product. Such intrinsically clean processes seem still hardly attainable at present. But it is expected from the ingenuity and resourcefulness of chemists that the chemical industry replaces many existing processes with new technologies aiming at a zero environmental footprint. This is important for fine and pharmaceutical industries which use energy [7] and generate a significant amount of chemical waste. However it is probably even more important for large chemical industries which a few minutes carbon footprint equals a yearly carbon footprint of pharma enterprise [8]. The waste and energy problems must be solved in the near future because the waste generation and energy consumption are increasing strongly due to growth of the world population and increasing standards of living in emerging economies [9]."
The electronic version of this article is the complete one and can be found online at: http://www.sustainablechemicalprocesses.com/content/1/1/18
Image source: http://wastebiorefining.blogspot.hk/2011_10_01_archive.html
Laboratório Nacional de Energia e Geologia, Unidade de Bioenergia, 1649-038, Lisboa, Portugal
[more about author]
Sustainable Chemical Processes 2013, 1:18 doi:10.1186/2043-7129-1-18
Excerpt
"Among the several definitions of biorefinery, the most widely used and recently accomplished by International Energy Agency (IEA) Bioenergy Task 42 is “Biorefining is the sustainable processing of biomass into a spectrum of marketable products and energy”. The biorefinery is an industrial facility (or network of facilities) that cover an extensive range of combined technologies aiming to full sustainable transformation of biomass into their building blocks with the concomitant production of biofuels, energy, chemicals and materials, preferably of added-value [4]. The biorefinery concept embraces a whole crop approach of biomass conversion pathways leading to a whole portfolio of valuable products, drawing direct similarities to today’s fossil oil refineries, in which multiple fuels, basic chemicals, intermediate products and sophisticated products are produced from petroleum [5,6]. To accomplish these needs science developed many less energy-requiring and less waste-generation technologies. However, still need of a new investment requirements and a perceived high risk of adoption of new technologies are slowing down the implementation of new processes. The solution of this problem is the development of more sustainable technologies that significantly increase the resource efficiency of chemical processes and reduce the operation time of such technologies. In addition, these new technologies should be accomplished in chemical industries by the introduction of chemical processes that do not produce contaminants, but only non-toxic commodities and recyclable or easily degradable materials. Industries should be based on ideal processes that start from non-polluting starting materials, lead to no secondary or concomitant products and require no solvents in order to carry out any chemical conversion or to isolate and purify the product. Such intrinsically clean processes seem still hardly attainable at present. But it is expected from the ingenuity and resourcefulness of chemists that the chemical industry replaces many existing processes with new technologies aiming at a zero environmental footprint. This is important for fine and pharmaceutical industries which use energy [7] and generate a significant amount of chemical waste. However it is probably even more important for large chemical industries which a few minutes carbon footprint equals a yearly carbon footprint of pharma enterprise [8]. The waste and energy problems must be solved in the near future because the waste generation and energy consumption are increasing strongly due to growth of the world population and increasing standards of living in emerging economies [9]."
The electronic version of this article is the complete one and can be found online at: http://www.sustainablechemicalprocesses.com/content/1/1/18
Image source: http://wastebiorefining.blogspot.hk/2011_10_01_archive.html
Landing on a comet - Rosetta and Philae
It is a historical moment after Philae vehicle landed successfully onto Comet 67P/Churyumov-Gerasimenko's surface.

Rosetta satellite has flown for 10 years. How the technology 10 years ago achieve this mention?
Take a look here:
The Rosetta Lander
PHILAE’S MISSION AT COMET 67P
However, the landing is not that smooth and Philae bounced twice and now located under a permanently shadow of a cliff, making it hard to gain enough sunlight for its power.
image source http://www.esa.int/Our_Activities/Space_Science/Rosetta/The_Rosetta_lander
Rosetta satellite has flown for 10 years. How the technology 10 years ago achieve this mention?
Take a look here:
The Rosetta Lander
PHILAE’S MISSION AT COMET 67P
Here is another interesting video by ESA:
- Using LEGO® to simulate ESA's touchdown on a comet
However, the landing is not that smooth and Philae bounced twice and now located under a permanently shadow of a cliff, making it hard to gain enough sunlight for its power.
image source http://www.esa.int/Our_Activities/Space_Science/Rosetta/The_Rosetta_lander
a Virus that 'Makes Humans More Stupid'
Corresponding author: Robert H. Yolken rhyolken@gmail.com
More about Robert H. Yolken

Significance
Human mucosal surfaces contain a wide range of microorganisms. The biological effects of these organisms are largely unknown. Large-scale metagenomic sequencing is emerging as a method to identify novel microbes. Unexpectedly, we identified DNA sequences homologous to virus ATCV-1, an algal virus not previously known to infect humans, in oropharyngeal samples obtained from healthy adults. The presence of ATCV-1 was associated with a modest but measurable decrease in cognitive functioning. A relationship between ATCV-1 and cognitive functioning was confirmed in a mouse model, which also indicated that exposure to ATCV-1 resulted in changes in gene expression within the brain. Our study indicates that viruses in the environment not thought to infect humans can have biological effects.
What to know more?
Chlorovirus ATCV-1 is part of the human oropharyngeal virome and is associated with changes in cognitive functions in humans and mice
Abstract
Chloroviruses (family Phycodnaviridae) are large DNA viruses known to infect certain eukaryotic green algae and have not been previously shown to infect humans or to be part of the human virome. We unexpectedly found sequences homologous to the chlorovirus Acanthocystis turfacea chlorella virus 1 (ATCV-1) in a metagenomic analysis of DNA extracted from human oropharyngeal samples. These samples were obtained by throat swabs of adults without a psychiatric disorder or serious physical illness who were participating in a study that included measures of cognitive functioning. The presence of ATCV-1 DNA was confirmed by quantitative PCR with ATCV-1 DNA being documented in oropharyngeal samples obtained from 40 (43.5%) of 92 individuals. The presence of ATCV-1 DNA was not associated with demographic variables but was associated with a modest but statistically significant decrease in the performance on cognitive assessments of visual processing and visual motor speed. We further explored the effects of ATCV-1 in a mouse model. The inoculation of ATCV-1 into the intestinal tract of 9–11-wk-old mice resulted in a subsequent decrease in performance in several cognitive domains, including ones involving recognition memory and sensory-motor gating. ATCV-1 exposure in mice also resulted in the altered expression of genes within the hippocampus. These genes comprised pathways related to synaptic plasticity, learning, memory formation, and the immune response to viral exposure.
⓿ The electronic version of this article is the complete one and can be found online at: http://www.pnas.org/content/111/45/16106.abstract#corresp-1
image source: Meet chlorovirus ATCV-1, a virus that can make humans more stupid
More about Robert H. Yolken
Human mucosal surfaces contain a wide range of microorganisms. The biological effects of these organisms are largely unknown. Large-scale metagenomic sequencing is emerging as a method to identify novel microbes. Unexpectedly, we identified DNA sequences homologous to virus ATCV-1, an algal virus not previously known to infect humans, in oropharyngeal samples obtained from healthy adults. The presence of ATCV-1 was associated with a modest but measurable decrease in cognitive functioning. A relationship between ATCV-1 and cognitive functioning was confirmed in a mouse model, which also indicated that exposure to ATCV-1 resulted in changes in gene expression within the brain. Our study indicates that viruses in the environment not thought to infect humans can have biological effects.
What to know more?
Chlorovirus ATCV-1 is part of the human oropharyngeal virome and is associated with changes in cognitive functions in humans and mice
Abstract
Chloroviruses (family Phycodnaviridae) are large DNA viruses known to infect certain eukaryotic green algae and have not been previously shown to infect humans or to be part of the human virome. We unexpectedly found sequences homologous to the chlorovirus Acanthocystis turfacea chlorella virus 1 (ATCV-1) in a metagenomic analysis of DNA extracted from human oropharyngeal samples. These samples were obtained by throat swabs of adults without a psychiatric disorder or serious physical illness who were participating in a study that included measures of cognitive functioning. The presence of ATCV-1 DNA was confirmed by quantitative PCR with ATCV-1 DNA being documented in oropharyngeal samples obtained from 40 (43.5%) of 92 individuals. The presence of ATCV-1 DNA was not associated with demographic variables but was associated with a modest but statistically significant decrease in the performance on cognitive assessments of visual processing and visual motor speed. We further explored the effects of ATCV-1 in a mouse model. The inoculation of ATCV-1 into the intestinal tract of 9–11-wk-old mice resulted in a subsequent decrease in performance in several cognitive domains, including ones involving recognition memory and sensory-motor gating. ATCV-1 exposure in mice also resulted in the altered expression of genes within the hippocampus. These genes comprised pathways related to synaptic plasticity, learning, memory formation, and the immune response to viral exposure.
⓿ The electronic version of this article is the complete one and can be found online at: http://www.pnas.org/content/111/45/16106.abstract#corresp-1
image source: Meet chlorovirus ATCV-1, a virus that can make humans more stupid
IBIO-T 2014 5TH Asian Symposium On Innovative BIO-PRODUCTION AND BIOREFINERY in Tainan, TAIWAN ,NOV 9-11, 2014
I am here already, where are you?

Meet the top scholars in this fields...

Chancellor's Professor
Department of Chemical and Biomolecular Engineering
University of California, Los Angeles
Fellow, National Academy of Engineering, NAE, 2013

Professor
Department of Biotechnology
University of Natural Resources and Life Science, Vienna

Distinguished Professor
Dept of Chemical Engineering
National Cheng Kung University,Taiwan

Professor
Dept of Chemical Science and Engineering
Kobe University,Japan

Professor
Dept of Chemical Engineering
POSTECH, Korea

Professor
Institute of Chemical & Engineering Sciences,Singapore

Professor
Department of Chemical Engineering, Tsinghua University, China

Ji-Won Yang
Professor
Dept of Chemical and Biochemical Engineering
KAIST, Korea
Tag :
general,
Parallel Universe and Quantum Mechanics
One interesting topic to me recently is "parallel universe", which I learnt it from movies and story books when I was a kid.

Currently, Prof. Howard Wiseman from Griffith University, tried to explain this "strange" universe via quantum mechanics:
Phys. Rev. X 4, 041013
"Quantum mechanics provides our most fundamental description of nature, but there is a long-standing and passionate debate among physicists about what all the math “really” means. We provide an answer based on a very simple picture: The world we experience is just one of an enormous number of essentially classical worlds, and all quantum phenomena arise from a universal force of repulsion that prevents worlds from having identical physical configurations. Probabilities arise only because of our ignorance as to which world an observer occupies. This picture is all that is needed to explain bizarre quantum effects such as particles that tunnel through solid barriers and wave behavior in double-slit experiments.
Our “many-interacting-worlds” approach hinges on the assumption that interactions between deterministically evolving worlds cause all quantum effects. Each world is simply the position of particles in three-dimensional space, and each would evolve according to Newton’s laws if there were no interworld interactions. A surprising feature of our approach is that the formulation contains nothing that corresponds to the mysterious quantum wave function, except in the formal mathematical limit in which the number of worlds becomes infinitely large. Conversely, Newtonian mechanics corresponds to the opposite limit of just one world. Thus, our approach incorporates both classical and quantum theory. We perform numerical simulations and show that our approach can reproduce interference with a double slit. As few as two interacting worlds can result in quantumlike effects, such as tunneling through a barrier.
Our approach, which provides a new mental picture of quantum effects, will be useful in planning experiments to test and exploit quantum phenomena such as entanglement. Our findings include new algorithms for simulating such phenomena and may even suggest new ways to extend standard quantum mechanics (e.g., to include gravitation). Thus, while Richard Feynman may have had a point when he said “I think I can safely say that nobody understands quantum mechanics,” there is still much to be gained by trying to do so."
Can't understand? try these news articles...
Still no idea? try Youtube:
The True Science of Parallel Universes
The True Science of Parallel Universes
Keep searching, I found one more news:
Why would associations between cardiometabolic risk factors and depressive symptoms be linear?
Corresponding author: Peter de Jonge peter.de.jonge@umcg.nl
Interdisciplinary Center Psychopathology and Emotion Regulation (ICPE), University Medical Center Groningen (UMCG), University of Groningen, Groningen 9700 RB, the Netherlands
[more about author]
BMC Medicine 2014, 12:199 doi:10.1186/s12916-014-0199-x

Background
Medical science is all about associations. Science becomes relevant if we can predict a variable y in which we are interested, from a variable x that we have at hand. We aim to develop models capable of making the most accurate predictions, or in other words, to develop the best representations of reality. Modern medical research is centered on associations, with the particular aim to assess whether these associations are causal. Many forms of associations are possible and linear associations are only a particular case. Linearity of an association is, in fact, a rather strong assumption to be made and most associations are likely to be non-linear. Yet, the majority of statistical tests used in medical research are based on that assumption.
Dynamic systems
In 2012, Sugihara et al. published a paper on how causality may be detected in complex ecosystems [1]. Take as an example a pond. In the pond, there is a variety of animal life, including daphnia (’water fleas’), small prey fish and larger predator fish. The pond is an ecosystem in which the presence of several organisms is causally related: an increase in the number of daphnia may be followed by an increase in the number of small prey fish as their food potential has increased. This increase of small prey fish may be followed by an increase in predator fish, effectively reducing the number of small prey fish. By that time, the number of daphnia may have decreased as well, or further increased as a function of the reduction in small fish. These associations are not linear: the association between two variables depends on the magnitude of the two variables and the presence of other internal (in the example, the daphnia and prey fish under the influence of the presence of predator fish) and external variables (for example, water temperature). In this system, the numbers of daphnia and small fish may be positively correlated at some point in time but negatively correlated or not correlated at all at other time points. In other words, in a complex, dynamic system such as a pond, associations between causally linked variables are dynamic, and summarizing them in a single value based on a linear function would give an inadequate representation of the true relationships.
Linear and non-linear associations in medical research
In medical research, we are interested in associations between variables describing the functions of human organisms. The ways associations have been studied are notably different for ecosystems and human organisms. Medical research has mostly been based on small numbers of assessments of many individuals, while ecosystems are often studied as a single entity with many assessments over time. Nevertheless, it is likely that human organisms behave in rather similar ways as ecosystems: there are many interdependent variables, and the association between two of these variables may depend on the magnitude of these variables and the levels of external variables. Take as an example the association between physical activity and depressive symptoms. The linear model would assume that any association between the two would be independent of the magnitude of the two variables (that is, a certain unit of increase in physical activity would lead to a certain increase in mood). However, the reality would probably be that an increase in mood would be achieved particularly when a person does not exercise regularly and would start exercising. However, when someone already exhibits high levels of regular exercise, a further increase in activity level would probably not lead to much mood gains. In addition, the relationship between physical activity and mood is probably bidirectional, meaning that mood could influence physical activity as well. To further complicate matters, the associations between exercise and mood may, in part, depend on external variables too, for example season of the year. As both mood and exercise are probably variables that tend to normalize, there may be complex feedback loops over time that can only be modelled using non-linear techniques applied to repeated assessments of both variables.
The link between depression and cardiometabolic disease
It is well established that an association between depression and cardiometabolic diseases exists, and that this association is complex and bidirectional [2],[3]. The work by Jani et al., published in BMC Cardiovascular Disorders, is one of the first steps in attempting to clarify the nature of these associations [4]. In a large sample of individuals with cardiometabolic disease, Jani et al. examined the association between blood pressure, body mass index (BMI), cholesterol, and HbA1c and elevated depressive symptoms (that is, a score >7 on the depression subscale of the Hospital Anxiety and Depression Scale (HADS)). All associations were significant and non-linear; more specifically, they were J-shaped. This is remarkable as many of the cardiometabolic risk factors also have J-shaped associations with cardiovascular disease and mortality, for example as shown in [5]-[7]. While the meaning of these J-shaped associations are unclear at the moment, Jani et al. draw a pragmatic conclusion from their data: if the association between cardiometabolic risk factors and depression is J-shaped in this high-risk population, perhaps there is most use in depression screening in persons with either low or high cardiometabolic risk scores (if there is any use in screening).
⓿ The electronic version of this article is the complete one and can be found online at: http://www.biomedcentral.com/1741-7015/12/199
image source: CHAOS NATURAE: Chaos, Complexity and Alchemy
Interdisciplinary Center Psychopathology and Emotion Regulation (ICPE), University Medical Center Groningen (UMCG), University of Groningen, Groningen 9700 RB, the Netherlands
[more about author]
BMC Medicine 2014, 12:199 doi:10.1186/s12916-014-0199-x
Background
Medical science is all about associations. Science becomes relevant if we can predict a variable y in which we are interested, from a variable x that we have at hand. We aim to develop models capable of making the most accurate predictions, or in other words, to develop the best representations of reality. Modern medical research is centered on associations, with the particular aim to assess whether these associations are causal. Many forms of associations are possible and linear associations are only a particular case. Linearity of an association is, in fact, a rather strong assumption to be made and most associations are likely to be non-linear. Yet, the majority of statistical tests used in medical research are based on that assumption.
Dynamic systems
In 2012, Sugihara et al. published a paper on how causality may be detected in complex ecosystems [1]. Take as an example a pond. In the pond, there is a variety of animal life, including daphnia (’water fleas’), small prey fish and larger predator fish. The pond is an ecosystem in which the presence of several organisms is causally related: an increase in the number of daphnia may be followed by an increase in the number of small prey fish as their food potential has increased. This increase of small prey fish may be followed by an increase in predator fish, effectively reducing the number of small prey fish. By that time, the number of daphnia may have decreased as well, or further increased as a function of the reduction in small fish. These associations are not linear: the association between two variables depends on the magnitude of the two variables and the presence of other internal (in the example, the daphnia and prey fish under the influence of the presence of predator fish) and external variables (for example, water temperature). In this system, the numbers of daphnia and small fish may be positively correlated at some point in time but negatively correlated or not correlated at all at other time points. In other words, in a complex, dynamic system such as a pond, associations between causally linked variables are dynamic, and summarizing them in a single value based on a linear function would give an inadequate representation of the true relationships.
Linear and non-linear associations in medical research
In medical research, we are interested in associations between variables describing the functions of human organisms. The ways associations have been studied are notably different for ecosystems and human organisms. Medical research has mostly been based on small numbers of assessments of many individuals, while ecosystems are often studied as a single entity with many assessments over time. Nevertheless, it is likely that human organisms behave in rather similar ways as ecosystems: there are many interdependent variables, and the association between two of these variables may depend on the magnitude of these variables and the levels of external variables. Take as an example the association between physical activity and depressive symptoms. The linear model would assume that any association between the two would be independent of the magnitude of the two variables (that is, a certain unit of increase in physical activity would lead to a certain increase in mood). However, the reality would probably be that an increase in mood would be achieved particularly when a person does not exercise regularly and would start exercising. However, when someone already exhibits high levels of regular exercise, a further increase in activity level would probably not lead to much mood gains. In addition, the relationship between physical activity and mood is probably bidirectional, meaning that mood could influence physical activity as well. To further complicate matters, the associations between exercise and mood may, in part, depend on external variables too, for example season of the year. As both mood and exercise are probably variables that tend to normalize, there may be complex feedback loops over time that can only be modelled using non-linear techniques applied to repeated assessments of both variables.
The link between depression and cardiometabolic disease
It is well established that an association between depression and cardiometabolic diseases exists, and that this association is complex and bidirectional [2],[3]. The work by Jani et al., published in BMC Cardiovascular Disorders, is one of the first steps in attempting to clarify the nature of these associations [4]. In a large sample of individuals with cardiometabolic disease, Jani et al. examined the association between blood pressure, body mass index (BMI), cholesterol, and HbA1c and elevated depressive symptoms (that is, a score >7 on the depression subscale of the Hospital Anxiety and Depression Scale (HADS)). All associations were significant and non-linear; more specifically, they were J-shaped. This is remarkable as many of the cardiometabolic risk factors also have J-shaped associations with cardiovascular disease and mortality, for example as shown in [5]-[7]. While the meaning of these J-shaped associations are unclear at the moment, Jani et al. draw a pragmatic conclusion from their data: if the association between cardiometabolic risk factors and depression is J-shaped in this high-risk population, perhaps there is most use in depression screening in persons with either low or high cardiometabolic risk scores (if there is any use in screening).
⓿ The electronic version of this article is the complete one and can be found online at: http://www.biomedcentral.com/1741-7015/12/199
image source: CHAOS NATURAE: Chaos, Complexity and Alchemy